
Thank you for visiting my website!
Costco always has great deals, but I am a sucker for their sales items. So often when I am shopping, I always check their online flyer (or go to the end of each aisle where the sales items are) and end up purchasing things that I definitely did not need. So my lovely husband suggested that a great project for me to work on would be to build a web scraper and alert system for the things I want but don’t want to pay full price for. He told me that it would be a great learning experience, but I think he just wanted me to stop buying random stuff we don’t need and filling our house with junk… Who’s to say what his true motives were, but away I went and started on this path. As with most beginner coding projects I definitely hit roadblocks and fell down some research rabbit holes, so I’ve written about the lessons learned but kept it a lot shorter than the deep research holes I fell into. In this post, we will be looking at grabbing data from the flyer section on costco.ca and then creating an alert when specific items appear on this list.
I have broken up the project into two parts:
Part 2: Comparing Costco Deals to Real Canadian Superstore Prices
Part 1: Pulling Costco Deal Item Details
I created a program that inputted each item one-by-one into the search bar and scraped the first item returned on the RCS. I chose to just pull the first item because it, theoretically, should be the closest match. Costco only has one bin that holds the brand name and item name, meaning that the name cannot be separated into two separate sections. Whereas, RCS has a bin for the brand and a bin for the item name, meaning that I was able to separate the brand name from the item name when storing it into the dataframe.
Initially, I ran the full name of the item through the search bar and stored the matched brand and item name in a data frame called “rcs_costco”.
Next, what I did was manually separate the brand from the item name for the Costco items and then ran a search with just the item name through RCS. I stored the brand name and the item name of both the Costco and RCS items in the “stripped_rcs_costco” data frame.
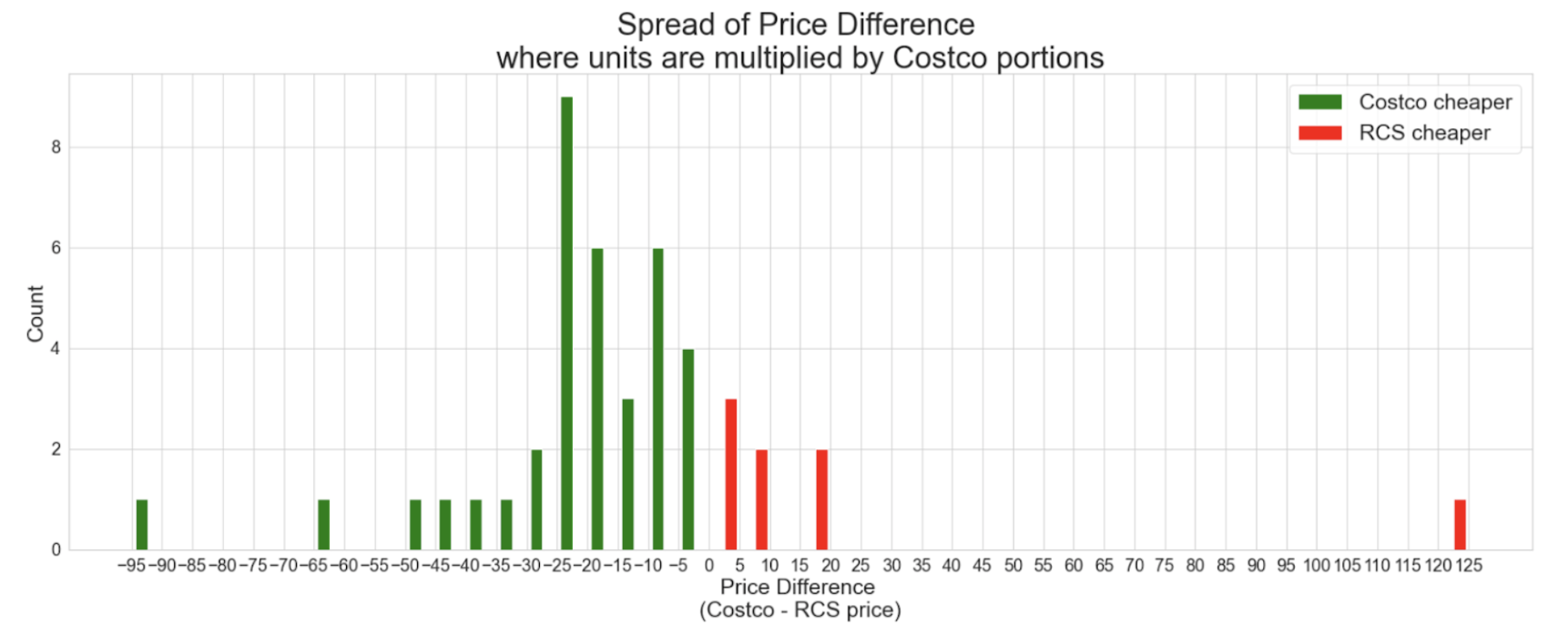
I wanted to know which data frame would be better to use based on which had more and better matches.
Right away, the items that did not have a brand name returned almost 2 times the amount of results (106 versus 54 iems). Then it was important to see how closely related the two items were from the different stores.
My first approach was to use NLTK. I compared the percentage similarities with both stopwords included and stopwords not included. When I analyzed the items that came back as a very high match vs a very low match there wasn’t a clear indication that the similarity percentage actually dictated the closeness of the items. So I abandoned this method.
Since I did not have many items (max of 106), I decided to go by hand and put 0 for not matched and 1 for matched, then proceeded to remove the not matches from the data frame (“matched_rcs_costco”).
Then I was able to start analyzing the data to get my answer to my question of are Costco deals really better?
As before we must import our libraries:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Then we have to specify what URL we will be using and access it using requests
URL = 'https://www.costco.ca/coupons.html'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
However, you will notice that this does not work. The reason it does not work is because costco.ca has information saved from cookies, so we must put in information before we use the get(). We specifically need a location for the Costco catalogue. Therefore, we must input the location cookies in order to access the flyer savings. The general work around of inputting via cookies (as can be found under my Fun Things Learnt → Cookies) does not work in this case and I had to further explore a new method. This is how I came to look at Selenium (how to set it up can be found under Libraries → Selenium).
As before we must import our libraries. I will list each of the packages I will be working with here at the start and quick description of what they do.
When we initially open the Costco webpage there is a pop-up asking for location and we must select which province we live in to get the correct flyers. So we must import selenium to allow us to interact with HTML elements, such as clicking on a page using automation.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
As seen in the set up of Selenium, we must specify where the web driver is located and create a variable that will call on the web driver for chrome (or whatever browser you have chosen to use).
path = "/Applications/chromedriver-92"
driver = webdriver.Chrome(path)
url = "https://www.costco.ca/"
For this section, I got a lot of help from a specific youtube programmer.
To access/open the webpage:
driver.get(url)
Here is a more clear picture of the source code for the location radio buttons:
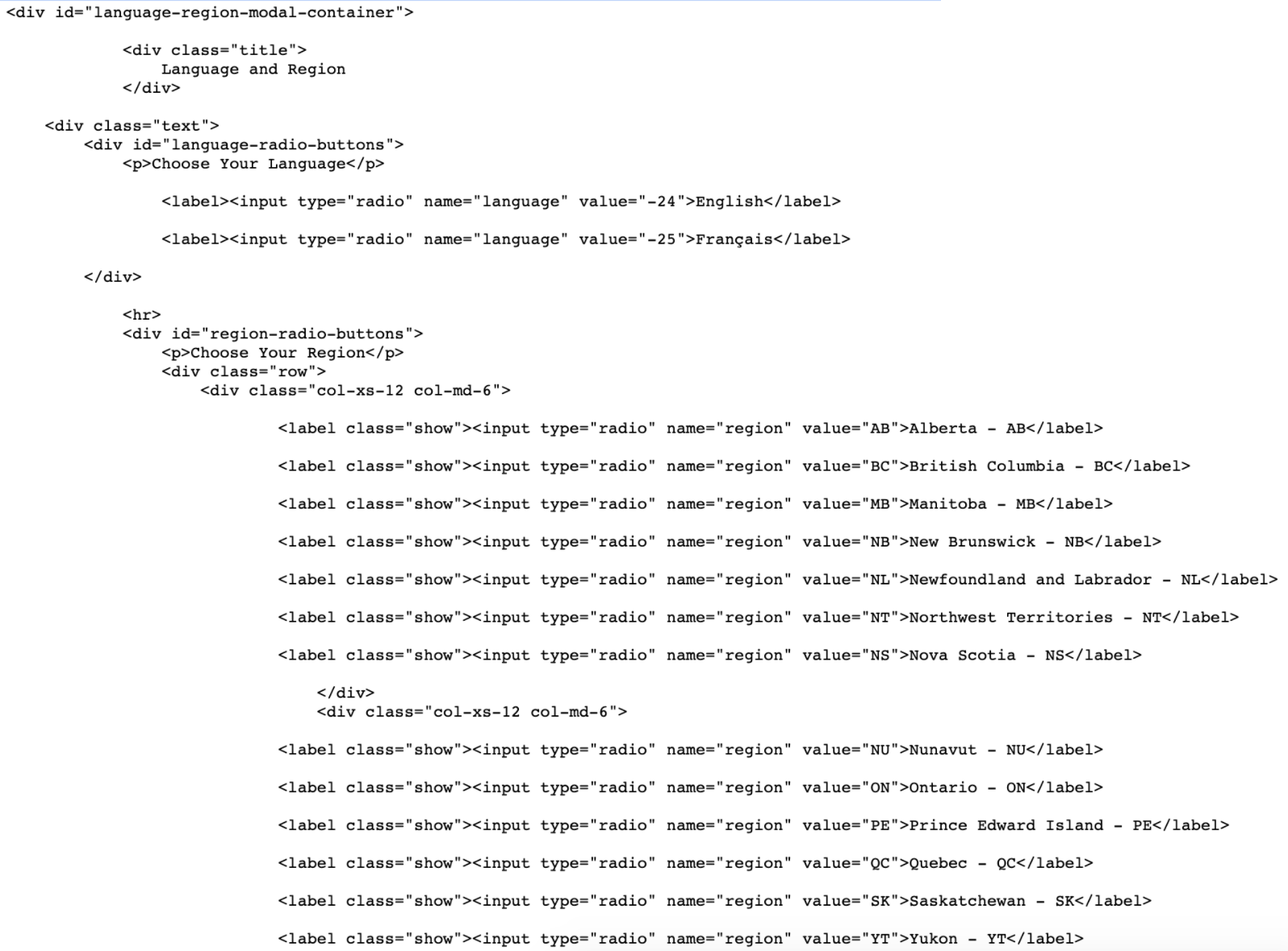
Finding elements using selenium can be done many different ways, for this we will be using xpath because the common ones we would normally use (finding by id, name, or class) will not be very useful since they are not unique. This tutorial really helped. Since the provinces are radio buttons, we must use the function .click(). We will be selecting Ontario for the purpose of this post.
We want to find the container/attribute that is different. In this case, we can see within the input container the value attribute is different based on the province/territory. So we are able to specify our path to be: //input[@value = 'ON']. // is to skip to the input container, [@value = ‘ON’] lets us select the specific attribute we want. (Side note - There is an easier way to get an xpath, which I go into in the pulling data section, but I think it is important to understand the process before taking shortcuts, hence why I wanted to show this). So our code would look like this:
select_region = driver.find_element_by_xpath("//input[@value = 'ON']").click()
Next we have to “click” the button that actually sets language and region:
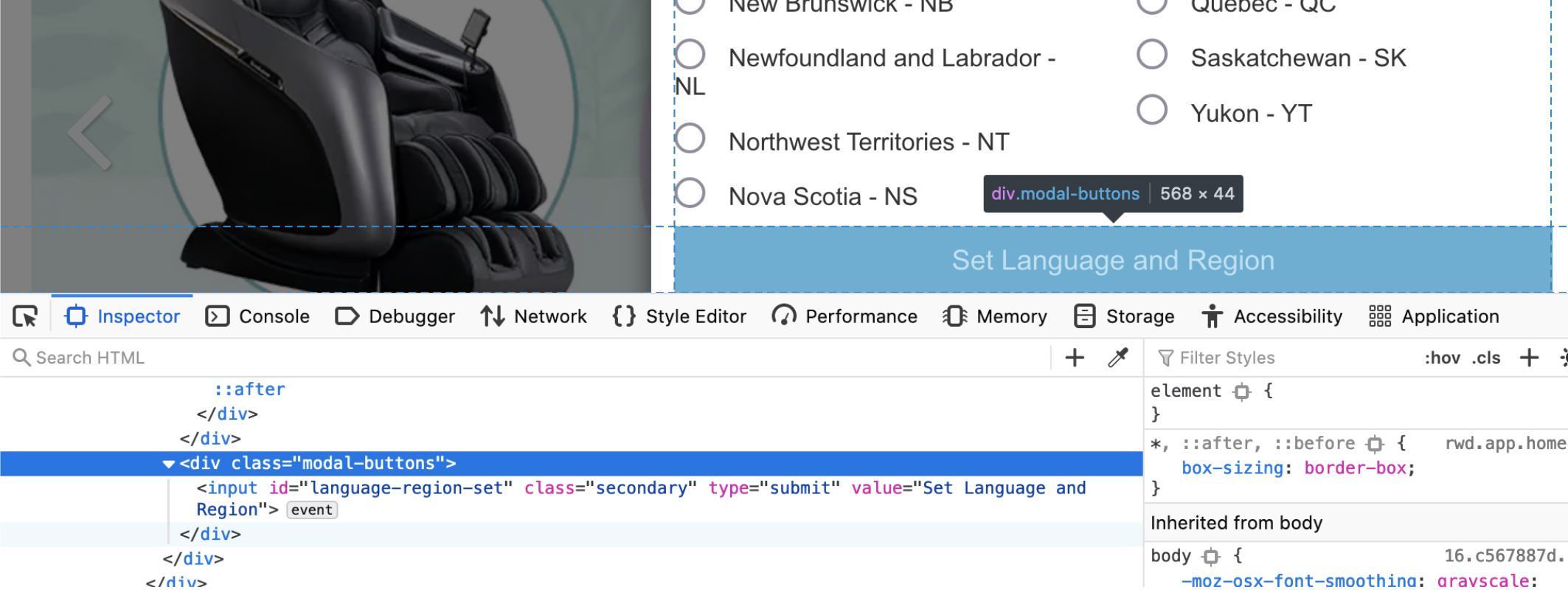
set_region = driver.find_element_by_xpath("//input[@value = 'Set Language and Region']").click()
Now we are in!
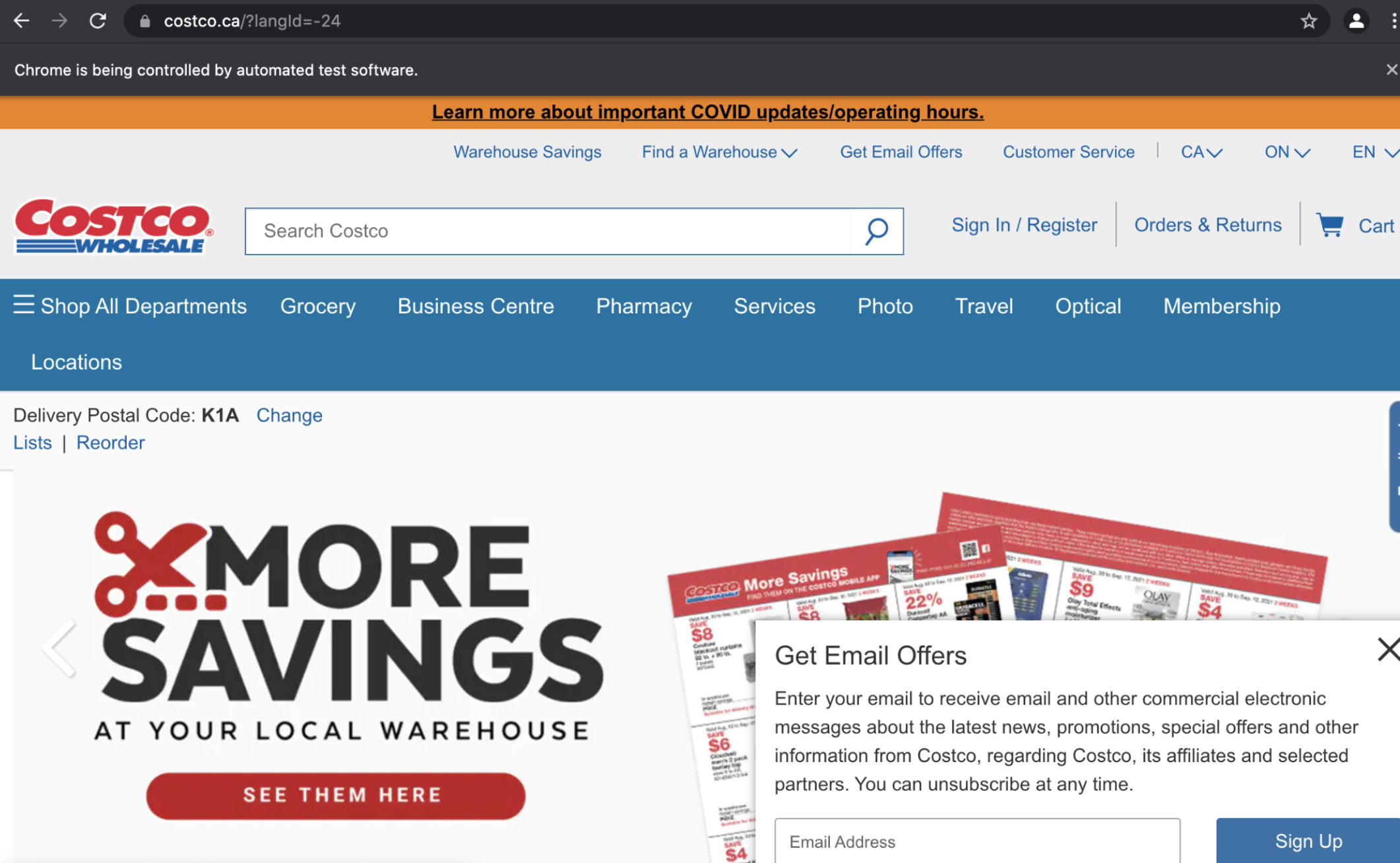
We still need to get to the “More Savings at your local warehouse”. This means that we would just have to search in the search bar for “coupons”, sure enough that brought me to the correct page that I want on the Costco website. So in order to find the search field in the page source, I did “cmd-f” for type="search" and found four results, of those 4 the one that I wanted had placeholder="Search Costco", so I knew this was the one I needed. Then since it has a unique id = “search-field”, I was able to find element by using the id search:
coupon_search = driver.find_element_by_id("search-field")
coupon_search.send_keys("coupon")
coupon_search.send_keys(Keys.RETURN)
When I clicked on the page manually, it brought me to this website: https://www.costco.ca/coupons.html. Then I realized, I didn’t need to go to the search bar to look for coupons because I already had the webpage for it. Lessons learned? Think before doing more. So back to my code I went and I edited the url and deleted the steps I just typed in the last paragraph. So here is the code so far:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
path = "/Applications/chromedriver-92"
driver = webdriver.Chrome(path)
url = "https://www.costco.ca/coupons.html"
driver.get(url)
select_region = driver.find_element_by_xpath("//input[@value = 'ON']").click()
set_region = driver.find_element_by_xpath("//input[@value = 'Set Language and Region']").click()
We need to make sure the page is fully loaded before we can try to pull the data from it, so we need to use wait.
First, we need to find the ID container:
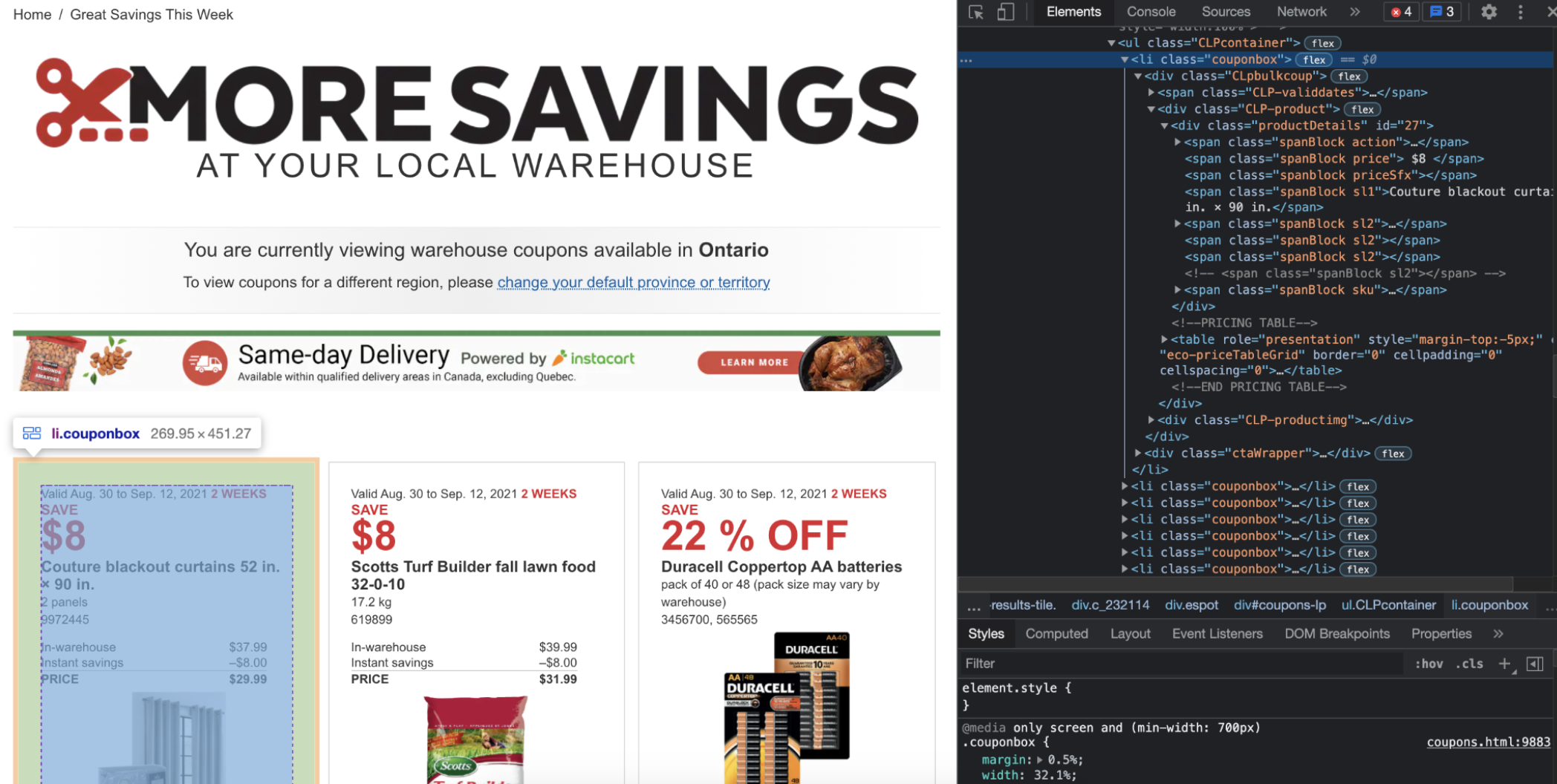
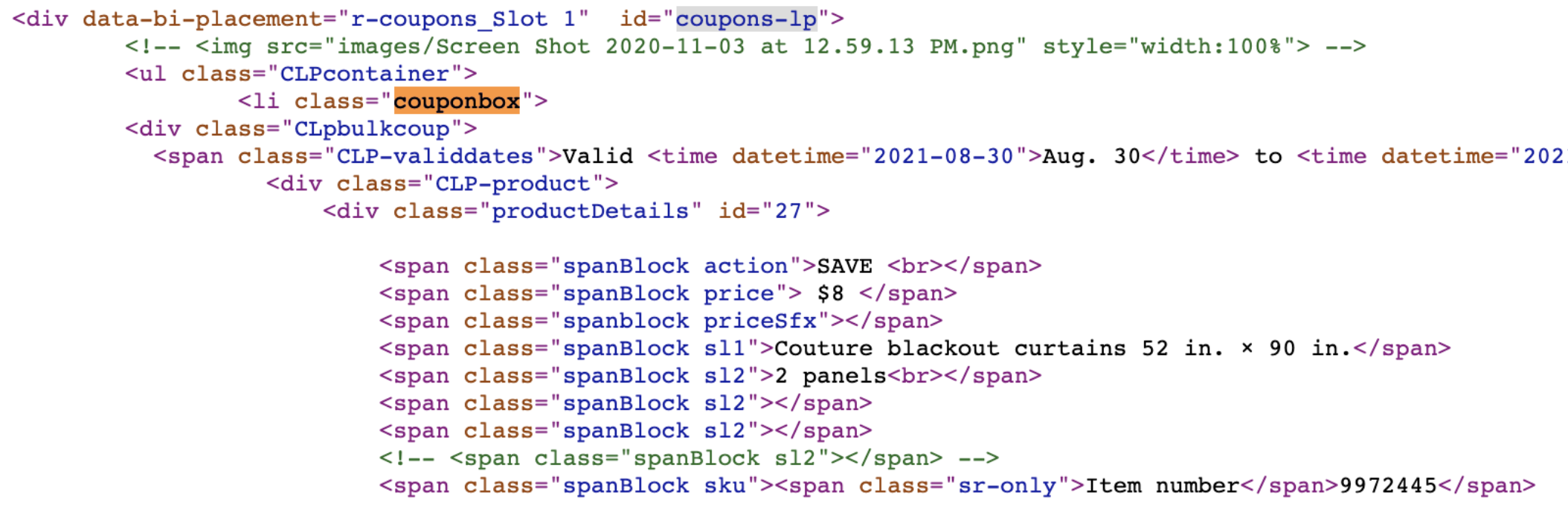
I pulled this code directly from the Selenium explicit wait function. I only changed two things:
try:all_coupons = WebDriverWait(driver, 10).until(finally:EC.presence_of_element_located((By.ID, "coupons-lp")))
CODE TO BE ADDEDdriver.quit()
Before we pull the data, we must create lists to store the information we want: product name, price, discount, start and end dates.
names = []
prices = []
savings = []
start_dates = []
end_dates = []
Now the following code that will be pulling the data from the container using various attributes will be all written within the try section.
We must find a container that contains all five of those details:
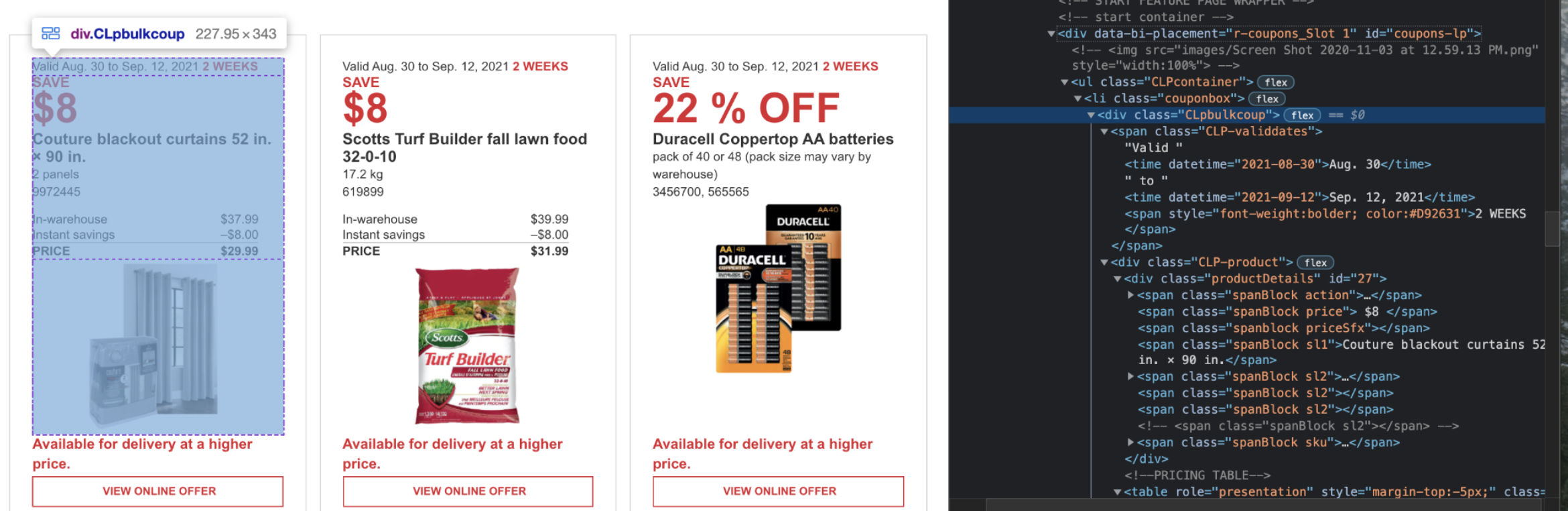
This “CLpbulkcoup” class contains the information we need for each individual coupon, so we want to find all elements (plural) that have this path. We will be using xpath to find all elements. On Chrome, you are able to copy the xpath and just paste it. This can cause errors depending on which path you have copied, so I always just use it as a starting point and then modify based on what I need.
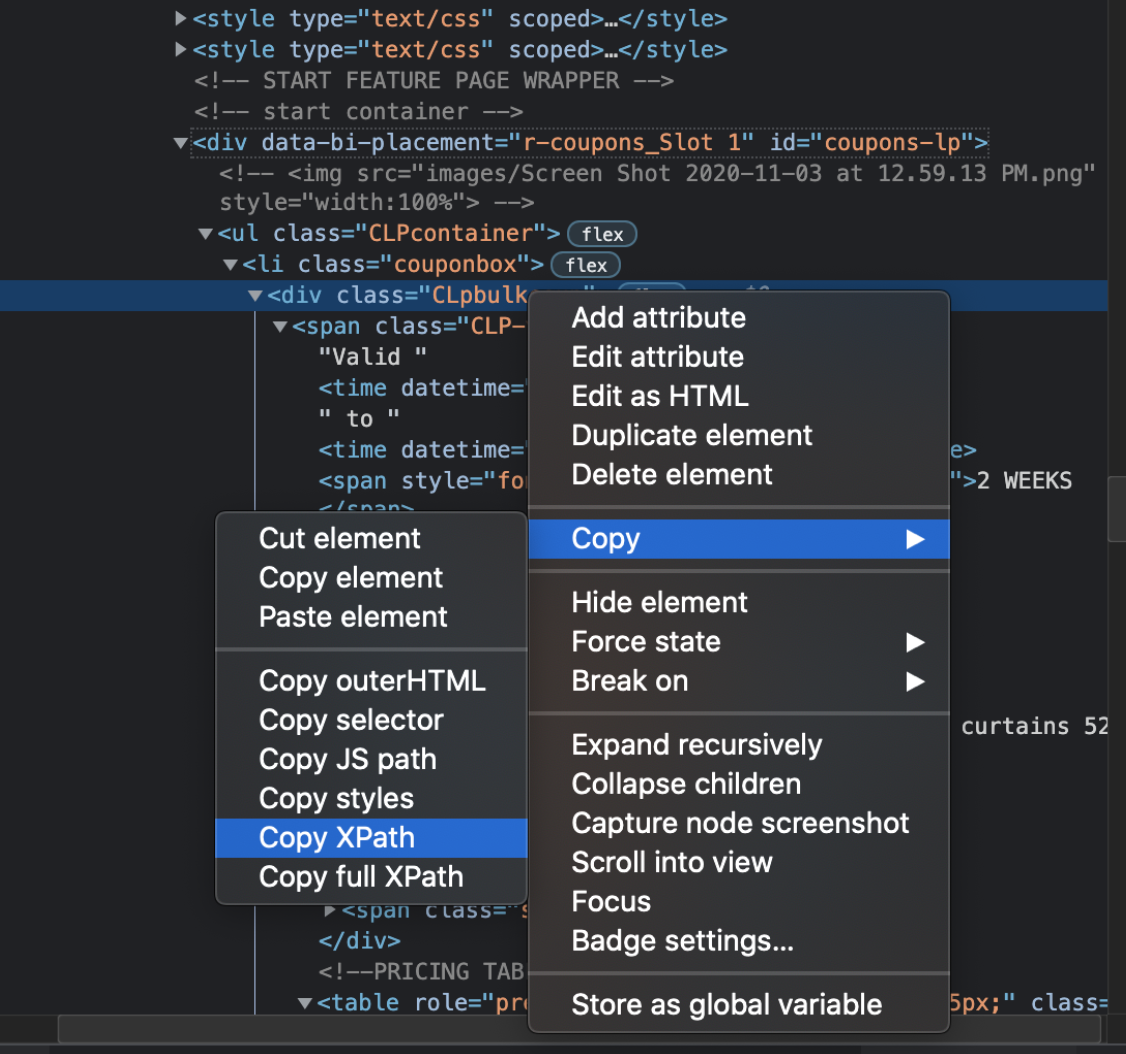
coupons_detail = all_coupons.find_elements_by_xpath("//div[@class='CLpbulkcoup']]")
We will be using a for-loop to cycle through each iteration of the coupons. I want to enumerate each item, so I can track if I have collected all the coupons and if they corresponded to the correct location. You do not need this for the code to work properly!
for i, coupon_detail in enumerate(coupons_detail):
Now, let’s breakdown how we will .find_element for each part we need:
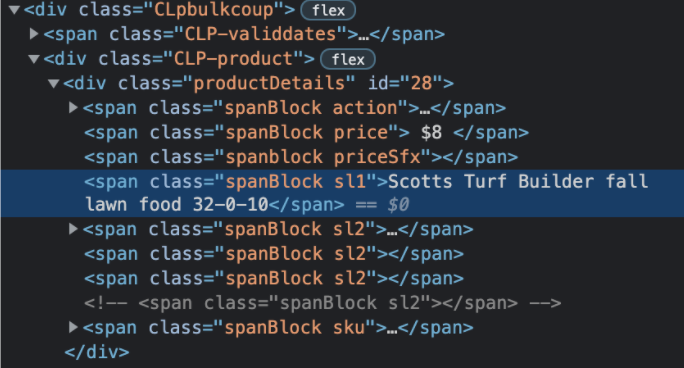
coupon_name = coupon_detail.find_element_by_class_name("sl1")
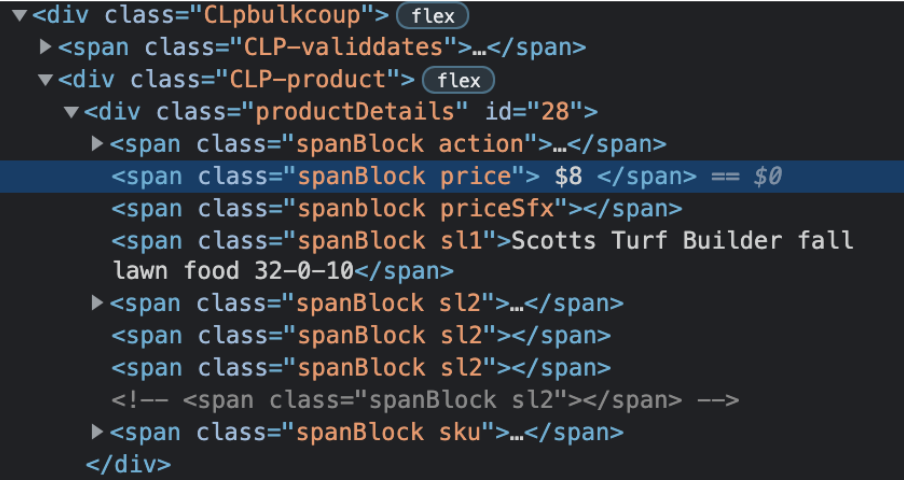
coupon_savings = coupon_detail.find_element_by_class_name("price")
For the new price extraction, I ran into issues primarily because the second coupon pulled did not have a price, only a % amount saved. So there was a lot of trial and error. First, I followed similar logic to what I had above:

coupon_price = coupon_detail.find_element_by_class_name("eco-priceTable")
What can be done now is import that exception and handle it. What that would look like is:
from selenium.common.exceptions import NoSuchElementException
try:coupon_price = coupon_detail.find_element_by_class_name("eco-priceTable")except NoSuchElementException:
print(coupon_price.text)coupon_price = None
We have to make sure we print the coupon_price.text in the try section because you cannot return .text of None attribute. The output I got was:
1) $39.99
3) $24.99
4) $12.69
5) $16.99
6) $16.99
7) $9.99
8) $11.49
9) $14.99
10) $11.99
...
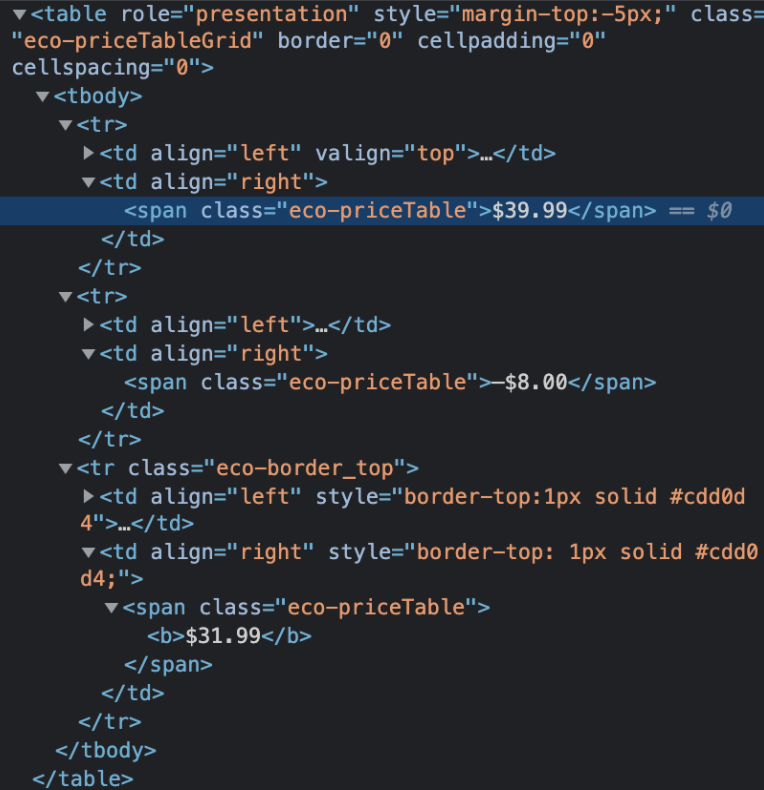
Now I learned something fancy (which in hindsight is really not that fancy but I was still very excited by it): you can find elements and specify which index of element you want in one line. How you ask? Well first we want to find all elements with the class “eco-priceTable”:
coupon_detail.find_elements_by_class_name("eco-priceTable")
find_elements_by_class_name("eco-priceTable")[2]
However, we run into an error because at least one of our examples does not have a price table, so we must account for it by specifying if there are no indices we will return none. First, we will store all the elements we have collected with the correct class name in the price_rows variable:
price_rows = coupon_detail.find_elements_by_class_name("eco-priceTable")
Then we can check if price_rows has data stored and store the third container text to give coupon_price or we set the coupon_price to None:
if price_rows:coupon_price = coupon_detail.find_elements_by_class_name("eco-priceTable")[2].textelse:coupon_price = None
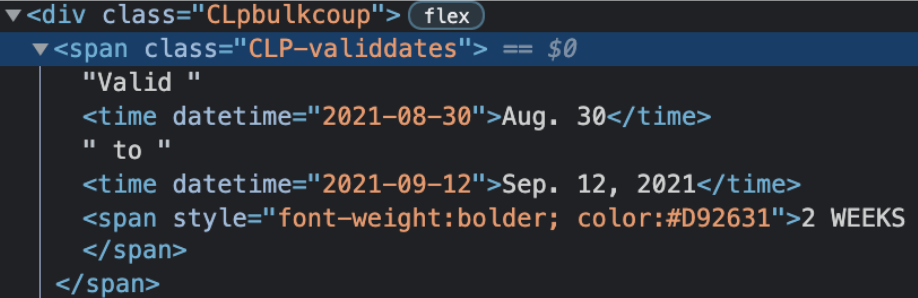
start_date = coupon_detail.find_element_by_xpath("//span[@class='CLP-validdates']/time[1]")
end_date = coupon_detail.find_element_by_xpath("//span[@class='CLP-validdates']/time[2]")
We must not only pull the data from each coupon, but we must also append the text of each entry to the correct list. So now that we have found all of the paths and ways to access the data we want, this is the code we will have:
coupon_name = coupon_detail.find_element_by_class_name("sl1").text
names.append(coupon_name)
coupon_savings = coupon_detail.find_element_by_class_name("price").text
savings.append(coupon_savings)
price_rows = coupon_detail.find_elements_by_class_name("eco-priceTable")
if price_rows:coupon_price = coupon_detail.find_elements_by_class_name("eco-priceTable")[2].textelse:coupon_price = Noneprices.append(coupon_price)
start_date = coupon_detail.find_element_by_xpath("//span[@class='CLP-validdates']/time[1]").text
start_dates.append(start_date)
end_date = coupon_detail.find_element_by_xpath("//span[@class='CLP-validdates']/time[2]").text
end_dates.append(end_date)
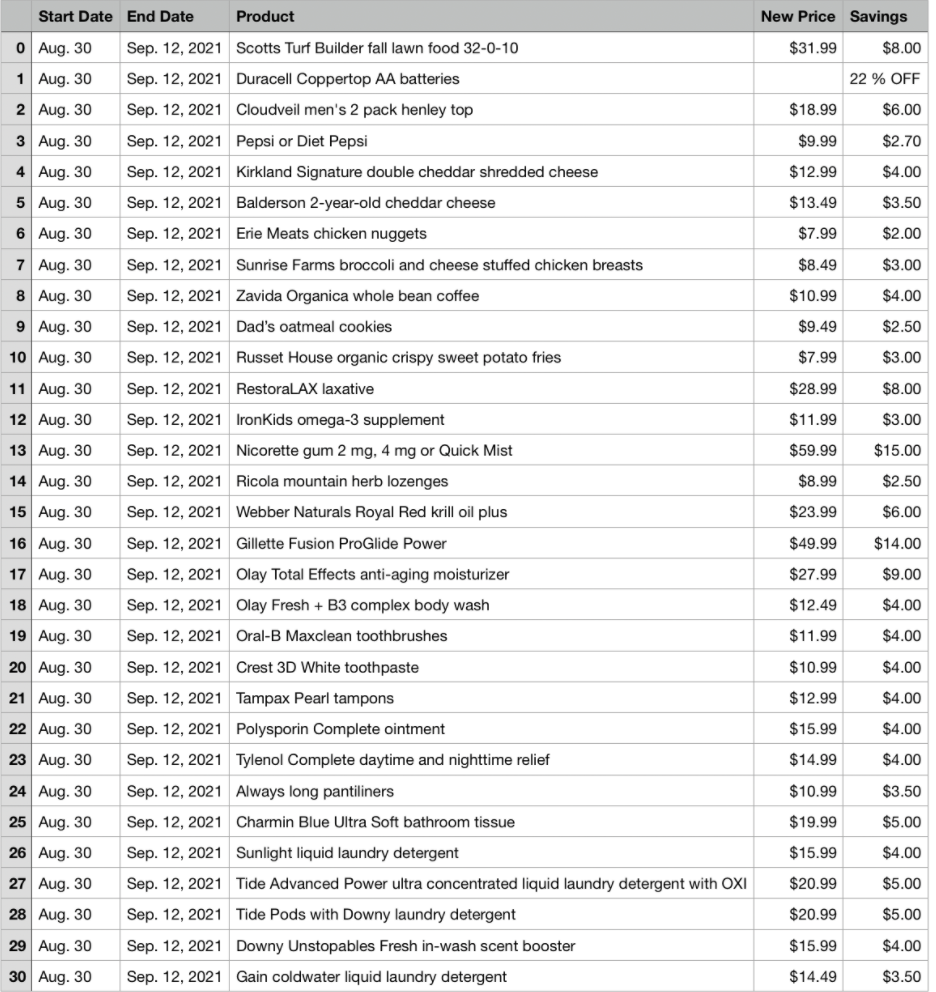
Now we just need to add the lists to a pandas dataframe:
coupons = pd.DataFrame({'Start Date' : start_dates,
'End Date' : end_dates,
'Product' : names,
'New Price' : prices,
'Savings' : savings,
})
Here is what our data frame looks like:
Now that we have all the data collected it is time to search for our keyword. First, let's set what our key word is (for testing purposes, we will pick chicken, as there are two iterations of it in the data):
key_word = "chicken"
Pandas has a series string finder, which I found very helpful guidance on Geeks-for-Geeks. We will be adding a column ("Search") to the data to give us a number when a keyword is found. The number that is given in the column determines the character location of the word. If a result of -1 is shown, this means the word was not found.
coupons["Search"] = coupons["Product"].str.find(key_word)
If the key word I'm looking for was chicken, this is the result I would get:

Next, we will need to get the index of row(s), primarily we are looking for any row that has a value greater than -1 in the "Search" column. .loc[] in pandas allows us to find rows corresponding to specific set criteria. We need to specify the data frame we are working with (in this case coupons) along with what label we are looking for (in this case the column ‘Search’) and we want to only find values that are greater than -1.
relevant_coupons = coupons.loc[coupons['Search'] > -1].copy()
In order to print the data, I do not want it to have the "Search" column in what is displayed (for aesthetic reasons), so I had to drop a column. The .drop() method I am using has two parameters inputs: the first one being - the label of the column/row you want to drop and the second one being - whether you are dropping a row (axis = 0) or a column (axis = 1). So our code would look like this:
relevant_coupons = relevant_coupons.drop(['Search'], axis = 1)
Before we print the relevant_coupon data, we have to consider if the .loc[] will find nothing. So we want to make a if/else statement. We would expect it to be false if there was a key term found. So if the relevant_coupons.empty is false then we can 1) drop the ‘Search’ column and 2) print out the data (I add another print line just for aesthetics).
if not relevant_coupons.empty:relevant_coupons = relevant_coupons.drop(['Search'], axis = 1)
print(relevant_coupons)
print("\n ------------------------------------------------------------------------------------------ \n")
else:print("No coupons found")
print("\n ------------------------------------------------------------------------------------------ \n")
Here is the csv file output you would get for searching the word chicken:




The completed code you can get on my GitHub page.