
Thank you for visiting my website!
After the web scraping of the Indeed website, I decided to try to scrap a website that required multiple pages to be scrapped. This led to me hitting a wall. So as always, I turned to the trusty Google. I came across a different tutorial on web scraping, and even though I had already learnt the basics, I decided to try it out. This tutorial is very well written and easy to follow! Me being me, of course, had to look up stuff into more details so that I could completely understand where everything was coming from. So something that should have been a quick read, turned into me trying the code myself, and alternating some stuff along the way. I also learnt how to store the data I collected into a CSV file leading me to the beginnings of data analysis (Which is pretty cool, I say as a math nerd)! This project was written as a way for me to solidify information for myself. It does link back to the Indeed project in terms of what I am learning past what I learnt in the previous one. So I would recommend either reading the Indeed project I wrote before this one, or going to the tutorial I got information from!
Just like with the last web scraping project, we must import our libraries for web scraping (requests and BeautifulSoup):
import requests from bs4 import BeautifulSoup
Now that we will want to install our data packages. In this project we will want to install Pandas, which is used to assemble the data into a data frame, plus it allows us to clean and analyze the data.
pip install pandas
import pandas as pd
Since we are scraping a source where languages of movies can change based on location, we need to create a header variable to ensure it is in English:
headers = {"Accept-Language": "en-US, en;q=0.5"}
Just like before we need to specify the URL and we want to store the information from the webpage, so we will use requests .get() method. This time, we need to have extra parameters. We want to specify headers = headers because the headers that we have within the website could be a different language, so we want to ensure that we are putting in the headers variable we created above (to make sure it is English).
URL = 'https://www.imdb.com/search/title/?groups=top_1000&ref_=adv_prv'
results = requests.get(URL, headers = headers)
We will also have to parse our html, using BeautifulSoup:
soup = BeautifulSoup(results.text, 'html.parser')
print(soup.prettify())
So here is the code we get for the first part:

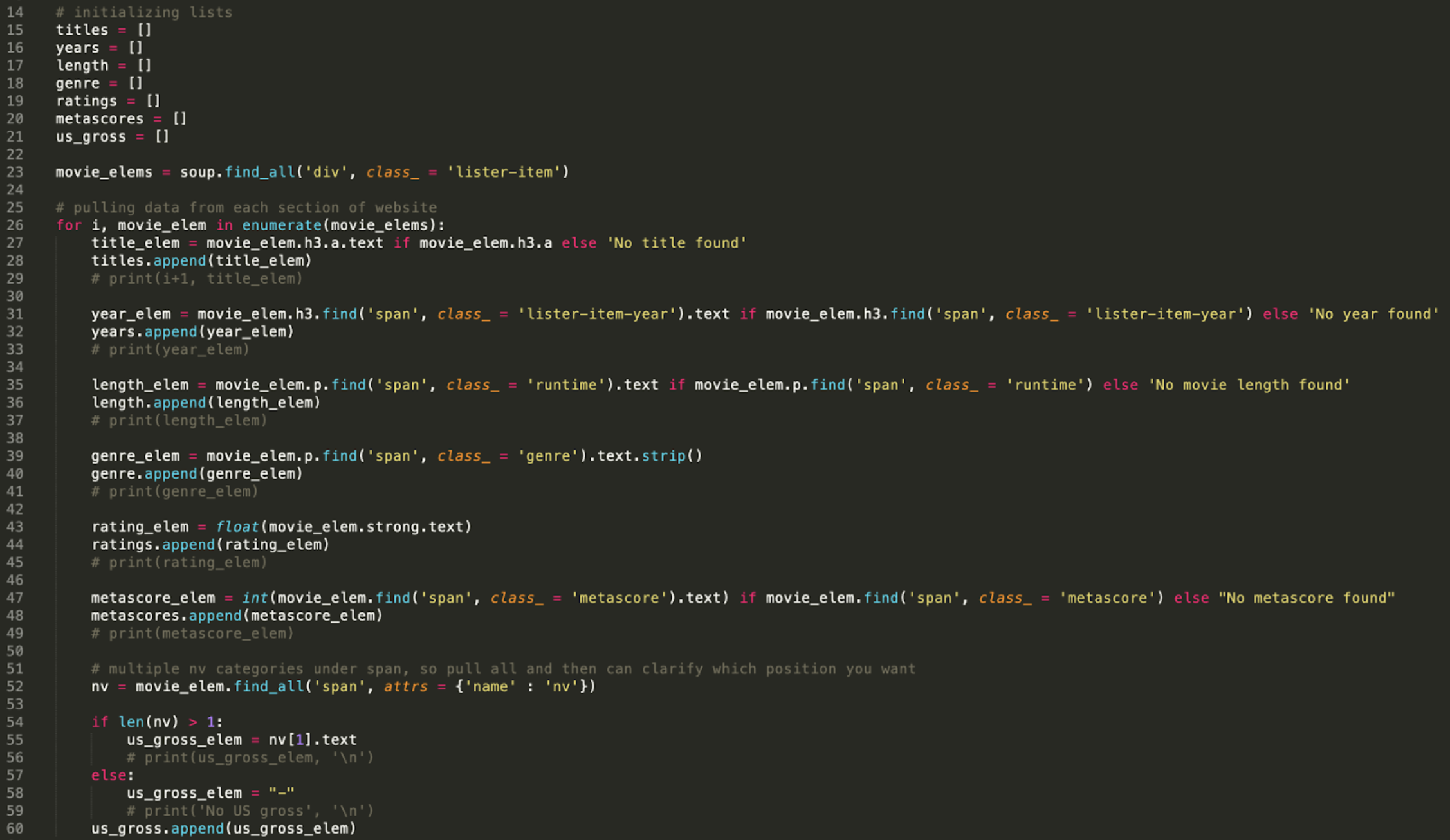
Now we will create lists to store the information we collect, rather than just printing it out. We want to initialize our lists. All you need to do to make a list is use “[]”. I wanted to get the following information: movie title, year released, length of movie, what genres it belongs to, the IMDb ratings, the metascore and how much did the movie make.
titles = []
years = []
length = []
genre = []
ratings = []
metascores = []
us_gross = []
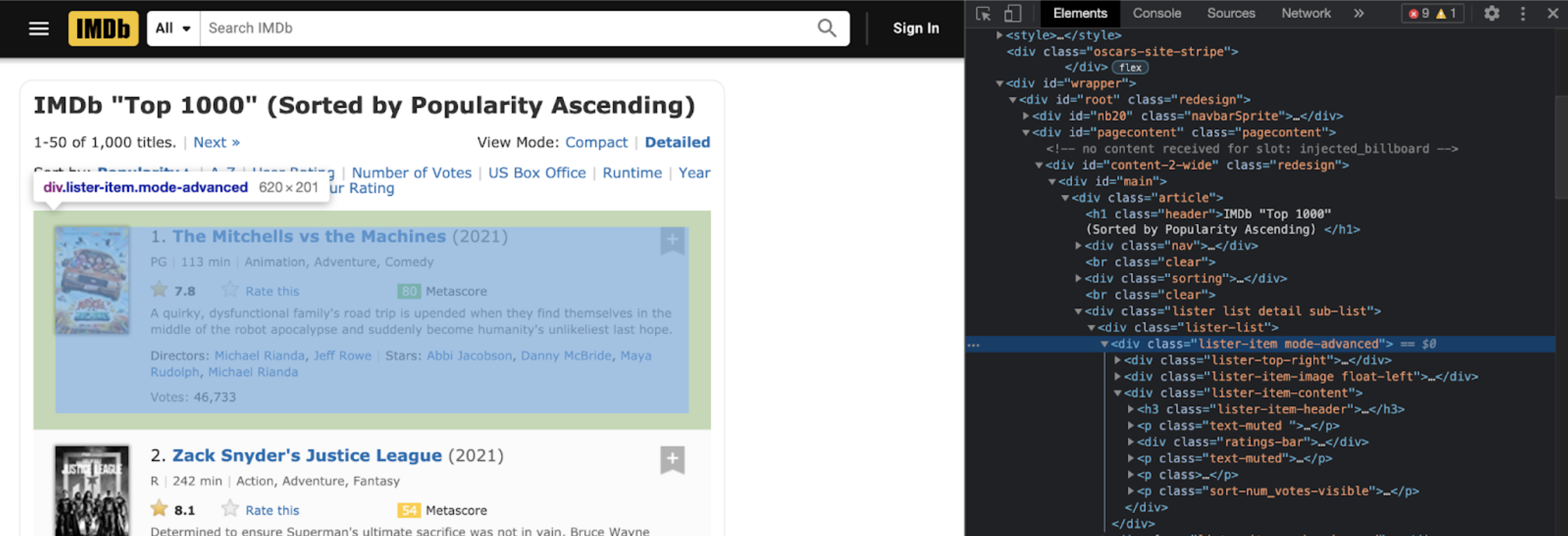
movie_elems = soup.find_all('div', class_ = 'lister-item')
Now in order to collect the specific data from the website, we will use a for-loop:
for i, movie_elem in enumerate(movie_elems):
In order to extract the title element, we look at the element source code, we see that it is contained within the h3 section:

title_elem = movie_elem.find('h3', class_ = 'lister-item-header').text.strip()
title_elem = movie_elem.h3.a.text
We need to ensure that there is no “none type” attribute, so we can error check right away:
if movie_elem.h3.a:title_elem = movie_elem.h3.a.textelse:title_elem = 'No title found'
title_elem = movie_elem.h3.a.text if movie_elem.h3.a else 'No title found'
titles.append(title_elem)

Next, we want to pull data from about the year it was released:

year_elem = movie_elem.h3.find('span', class_ = 'lister-item-year').text if movie_elem.h3.find('span', class_ = 'lister-item-year') else 'No year found'
years.append(year_elem)
To pull the runtime of the movie:

length_elem = movie_elem.p.find('span', class_ = 'runtime').text if movie_elem.p.find('span', class_ = 'runtime') else 'No movie length found'
length.append(length_elem)
To pull the genre:

genre_elem = movie_elem.p.find('span', class_ = 'genre').text.strip() genre.append(genre_elem)
To pull the ratings:

rating_elem = float(movie_elem.strong.text) ratings.append(rating_elem)
To pull the metascore:
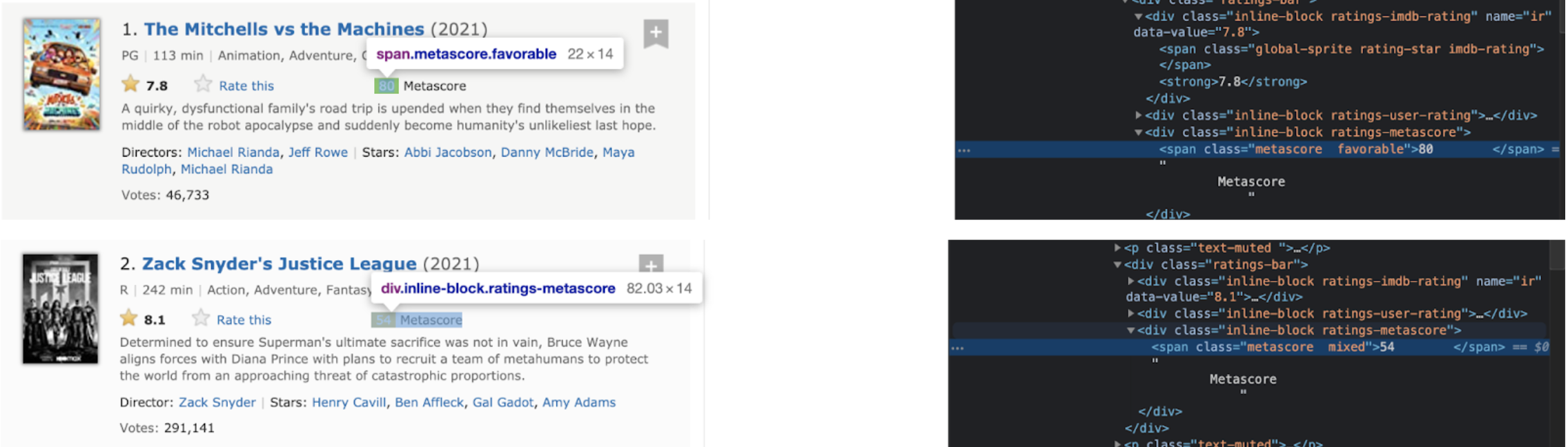
metascore_elem = int(movie_elem.find('span', class_ = 'metascore').text)
metascore_elem = int(movie_elem.find('span', class_ = 'metascore').text) if movie_elem.find('span', class_ = 'metascore') else "No metascore found"
metascores.append(metascore_elem)
Now when we look at the US gross worth, we can see that only some of the movies have it:

nv = movie_elem.find_all('span', name = 'nv')
We will get an error due to the fact that the name attribute is not unique. So we must specify that we are looking at more than one attribute, and that it contains both the ‘name’ and ‘nv’:
nv = movie_elem.find_all('span', attrs = {'name' : 'nv'})
Now that we have collected all the data values from the name attributes, we need to specify which one is the one we will use for the US gross. We can do this by checking how many ‘nv’ were collected by .find_all() method. We check if the length of nv is greater than 1 (meaning more than one data point was collected), using the len() function. If there is more than one entry, we want to just pull the second index. Remember for indices it starts at 0, so when we want the second index we denoted it with a 1: nv[1].
if len(nv) > 1:us_gross_elem = nv[1].text
else:us_gross_elem = "-"
us_gross.append(us_gross_elem)
Here is the code for step two:
Now that we have the data and it is stored in lists, we want to make a data frame to be able to edit the data and then we can move further to manipulate it. We will use Pandas to do this. Remember, that we imported Pandas at the start, but we gave it the variable pd, meaning when we reference it we just need to write “pd.” to access various functions from the Pandas library. I’ll quickly go over the format of Pandas DataFrame:
pandas.DataFrame({‘title of column 1’ : [what you want column 1 to contain],
‘title of column 2’ : [what you want column 2 to contain],
...
})
movies = pd.DataFrame({'movie' : titles,
'year' : years,
'length (min)' : length,
'genre' : genre,
'IMDb ratings' : ratings,
'Metascore' : metascores,
'US gross (millions)' : us_gross,
})
print(movies)
In this post it is not that important that the data types are correct as the data will not be used/manipulated. However, it is important to get into a good habit of making sure the data types are correct because you never know when you might go back to your data and need to manipulate and use it.
So first thing we will do is check which data types we have:
print(movies.dtypes)
movie object
year object
length object
genre object
IMDb ratings float64 *because I classified it as float() earlier
Metascore int64 *because I classified it as int() earlier
US gross object
As we can see we need to change some of these:
Let’s start with the year, we will want to remove the parenthesis that come with the year. So from the string we will want to just extract the number. ‘extract(\d+)’ says to start extracting at the 1st digit, "+" means that it must have at least 1 digit. If we did not care about the number of integers needed, we could have written ‘extract(\d*)’, where "*" means you can start at 0 integers. Next, after we have extracted the digits from the string, we want to use .astype() method to convert the string to an integer. We also want to write over the data we had previously in the list with our newly edited integers, so we will set the variable to be the same:
movies['year'] = movies['year'].str.extract('(\d+)').astype(int)
Now for movie length, we will do the same thing because we want to remove just the number and leave out the “min”:
movies['length (min)'] = movies['length (min)'].str.extract('(\d+)').astype(int)
For the US gross, the number we want is found in between $ and M, with a decimal in the number, so we cannot just use the str.extract() method that we used for the other two cases. When I did research on how to remove the $ and M, what I found was that I can use .str.replace() method as many times as I wanted. Where .str.replace(‘what you want to remove’, ‘what you want to put in instead’), so I tried:
movies['US gross (millions)'] = movies['US gross (millions)'].str.replace('M', '').str.replace('$', '')
Then we want make sure that the US gross is a float, which we use Pandas for:
movies['us_grossMillions'] = pd.to_numeric(movies['us_grossMillions'])
movies['us_grossMillions'] = pd.to_numeric(movies['us_grossMillions'], errors='coerce')
Now that that has been completed, the last thing we need to do is save it to a CSV file, so we can access it later and use the data (should we chose to).
movies.to_csv('IMDbmovies.csv')
movies.to_csv('/Users/anjawu/Code/imdb-web-scraping/IMDbmovies.csv')
Full code found here!