
Thank you for visiting my website!
After I finished with the hangman game, I decided I was very interested in how web scraping works. So I found a good tutorial on how to begin with scraping the Monster job website (I tried to link to it but the article no longer exists - it was written by Martin Breuss). Unfortunately, the Monster website had been changed since the article was posted so I had to do some digging and googling to be able to complete this tutorial. I did get a recommendation to try the Indeed job website. So that is what I will be going through here. Update: I found another article by the same author that was through the web scraping. I have not read through it or done the code, but I wanted to link it here because I liked how the original article was written, so I figured this one must be good too!
WARNING:
As with all tutorials that go through web scraping, I want to iterate that you need to be very careful about scraping websites, because each website has its own rules about if/how the data can be collected.
How can you check?
By adding “/robots.txt” to the end of the URL of the website you want to scrape. It will show you a list of parts of the website that they do not allow data to be scraped from. Most of the time as long as you’re scraping publicly available data you should be okay, but you still need to check!
Libraries needed for accessing data:
BeautifulSoup is a python language that allows you to get information from various languages, in our case HTML. In order to install it, you must go to your terminal and type:
pip install beautifulsoup4
pip install requests
URL:
Speaking of HTTP… I will be looking at the following website to scrape: https://ca.indeed.com/jobs?q=software+developer&l=ontario.
We can breakdown URLs to give us more context into the webpage we are looking at. For our specific example, we have the base URL: https://ca.indeed.com/jobs. Then we have “?” which specifies the query we are asking. In this case, we have two parts of the query. We can tell this because each piece is divided by an ampersand (&). The first part “q=software+developer” which specifies that we are looking at the job postings for software developer, the second part “l=ontario” tells us the location we are looking at is Ontario.
HTML code:
Next we want to get a basic understanding of what HTML code looks like.
In order to get the code for the website there are two ways to do it:
Remember how we installed BeautifulSoup and requests? Well now we have to import them into our program.
import requests
from bs4 import BeautifulSoup
URL = 'https://ca.indeed.com/jobs?q=software+developer&l=ontario'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
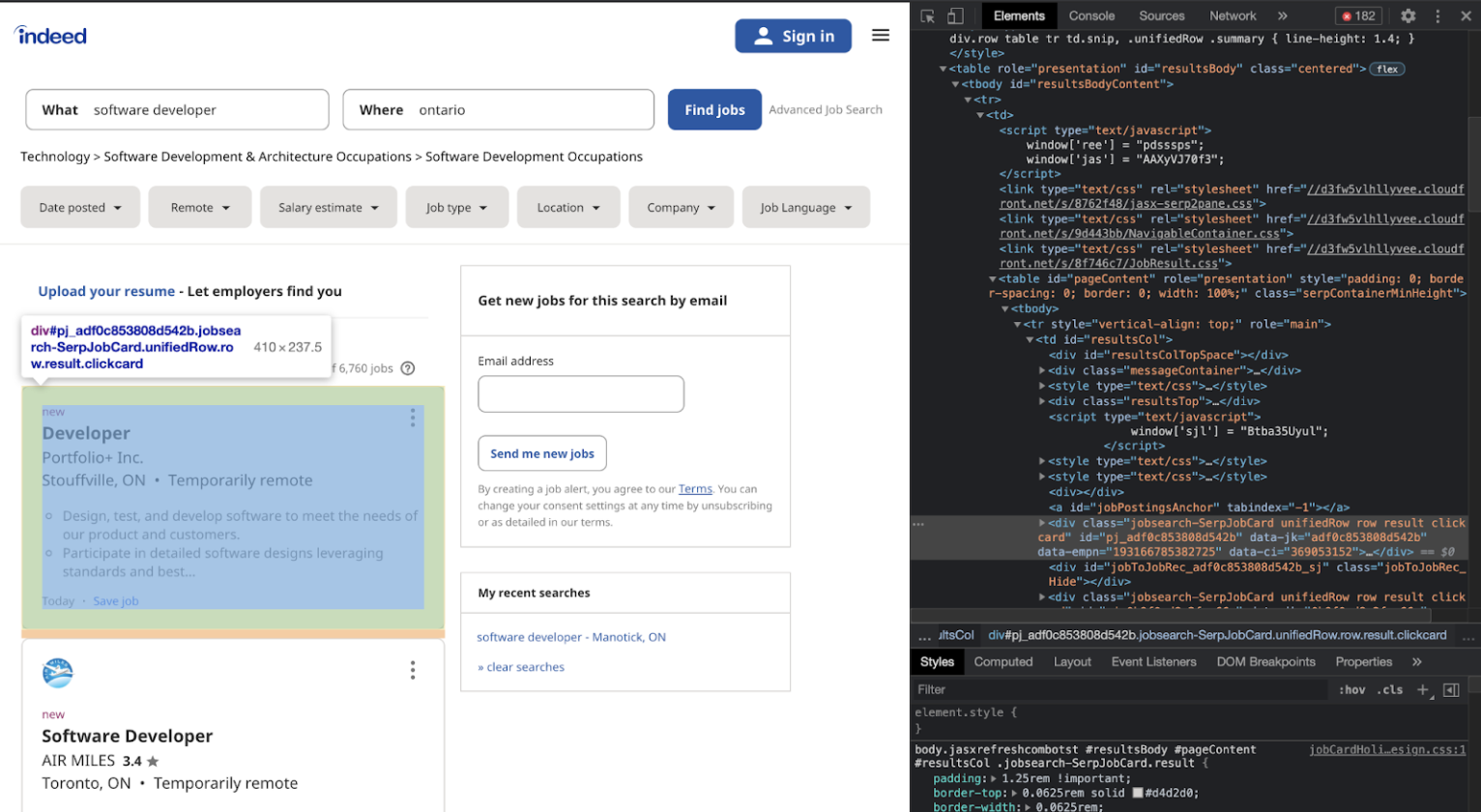
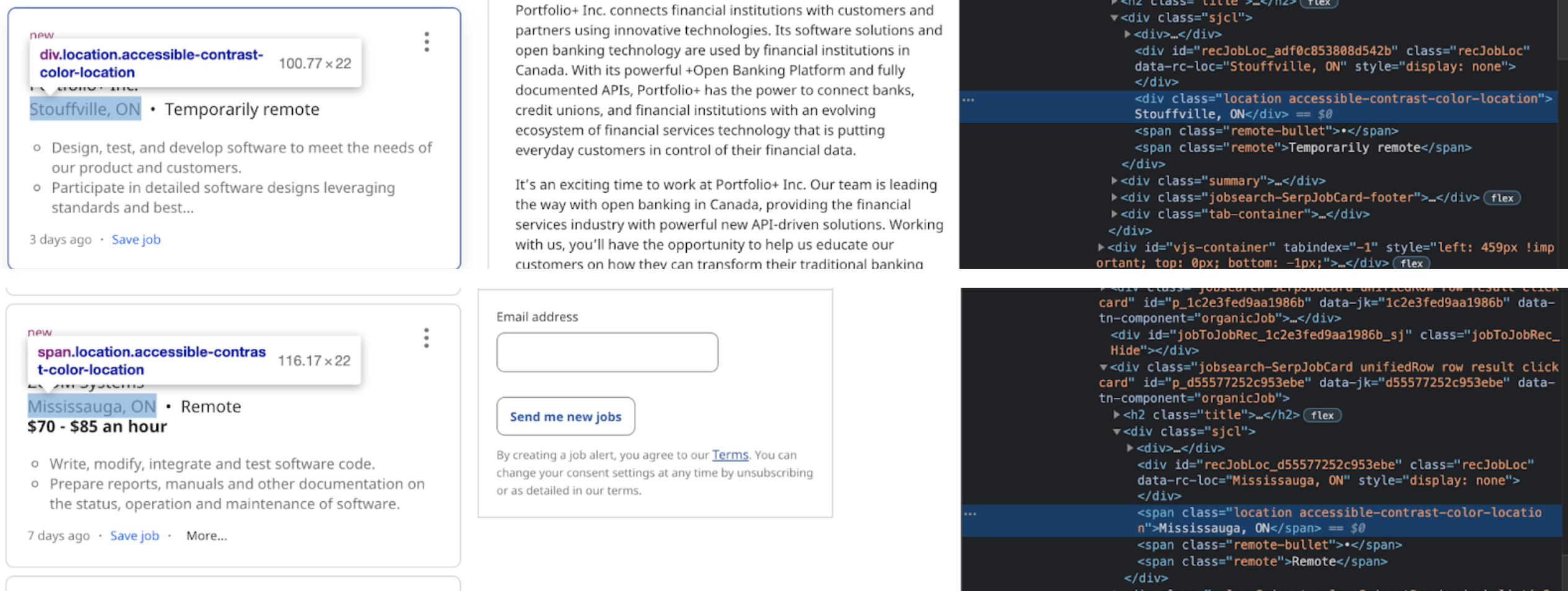
Now that we have parsed the information from the webpage, we want to start filtering the data we need. Looking at our elements code, I went through the code until just the results column was highlighted:
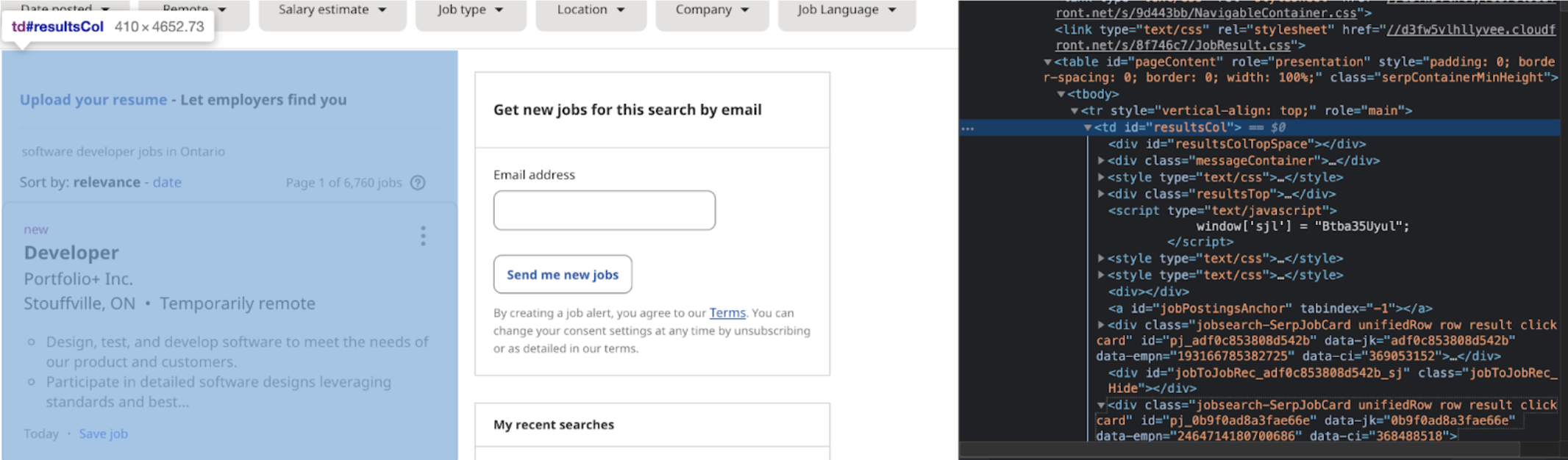
results = soup.find(id ='resultsCol')
print(results.prettify())
Here is my code from part 1:
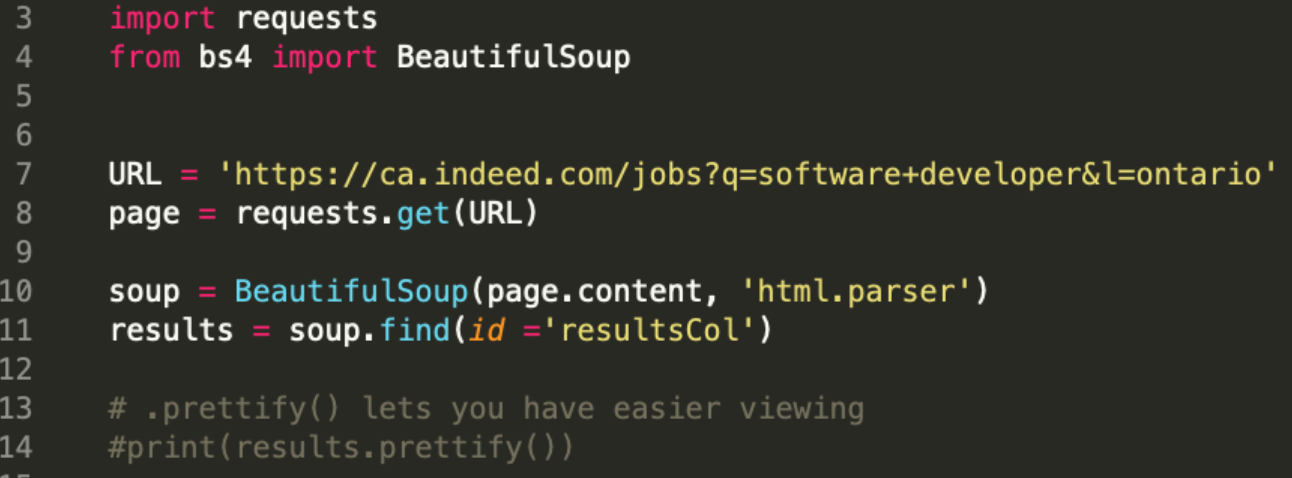
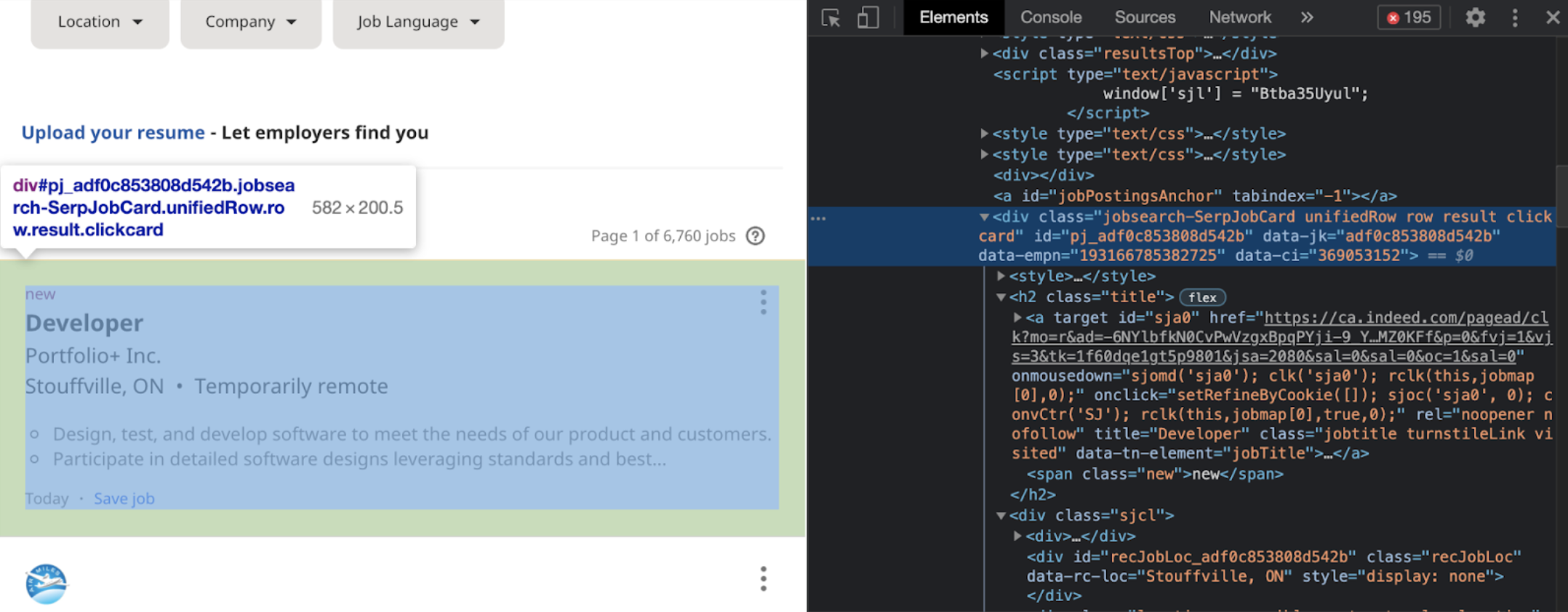
At the end of step one, we were able to get the data from the results column, now we must take more information out. Looking back at the HTML elements code:
If you look at the next job posting:
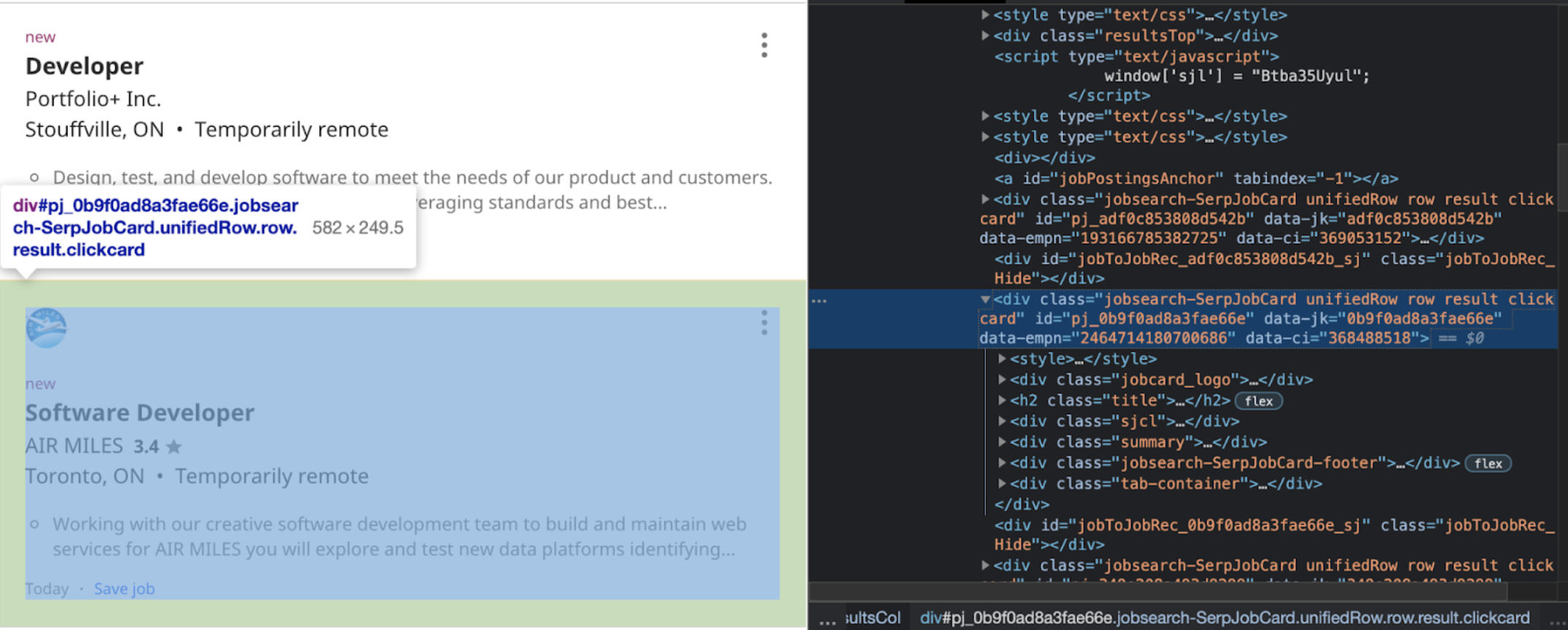
They are very similar, what changes is the identifying number. We can see that the div class = “jobsearch-SerpJobCard unifiedRow row result clickcard” remains the same. Meaning if we want to look at each individual job posting, we can call on the div class from above. We want to use the .find_all() method in order to ensure that we collect all the jobs listed under the specific tag. We can specify we are looking at the ‘div’ section, but there are a lot of div sections, so we have to be more specific; we want the other tag to also have class="jobsearch-SerpJobCard …”. So we would write it as:
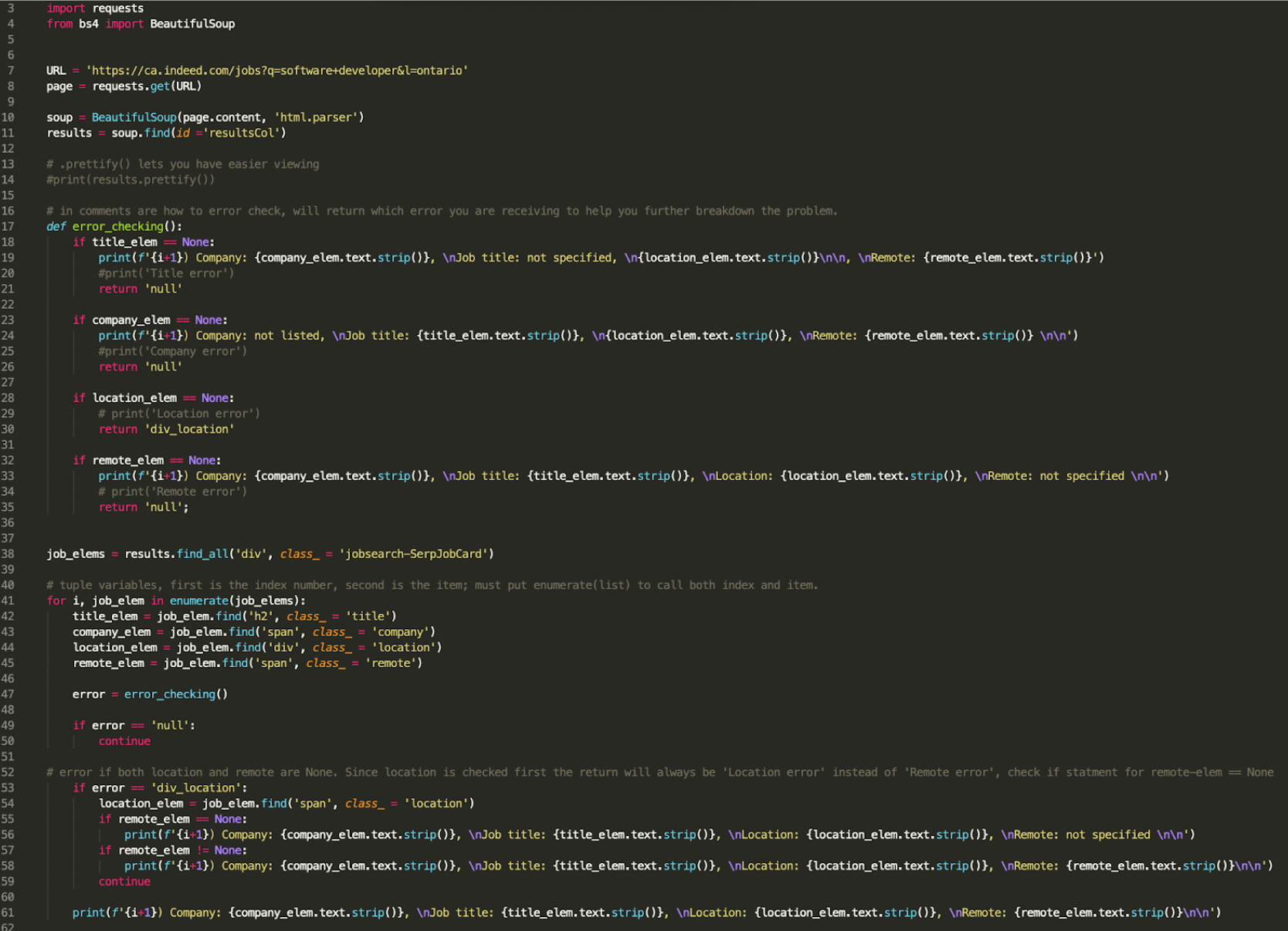
job_elems = results.find_all('div', class_ = 'jobsearch-SerpJobCard')
We store all the different aspects into the job_elems variable to signal that this variable will have all the job elements that we want. From this point, we want to get specific aspects of each job. In this case we want to use the .find() method because we want to cycle through and find the first one. We will use a for-loop to cycle through all parts of the job_elems. It would be enough to have the code be for job_elem in job_elems: but I also wanted to know how many jobs are being printed and I wanted to number them, so we write:
for i, job_elem in enumerate(job_elems):
Now, on to how we can get the specific parts that we want from each job. In this example I just wanted: job title, company name, where it is located, if it is remote. So we will look at those parts:
For the job title:
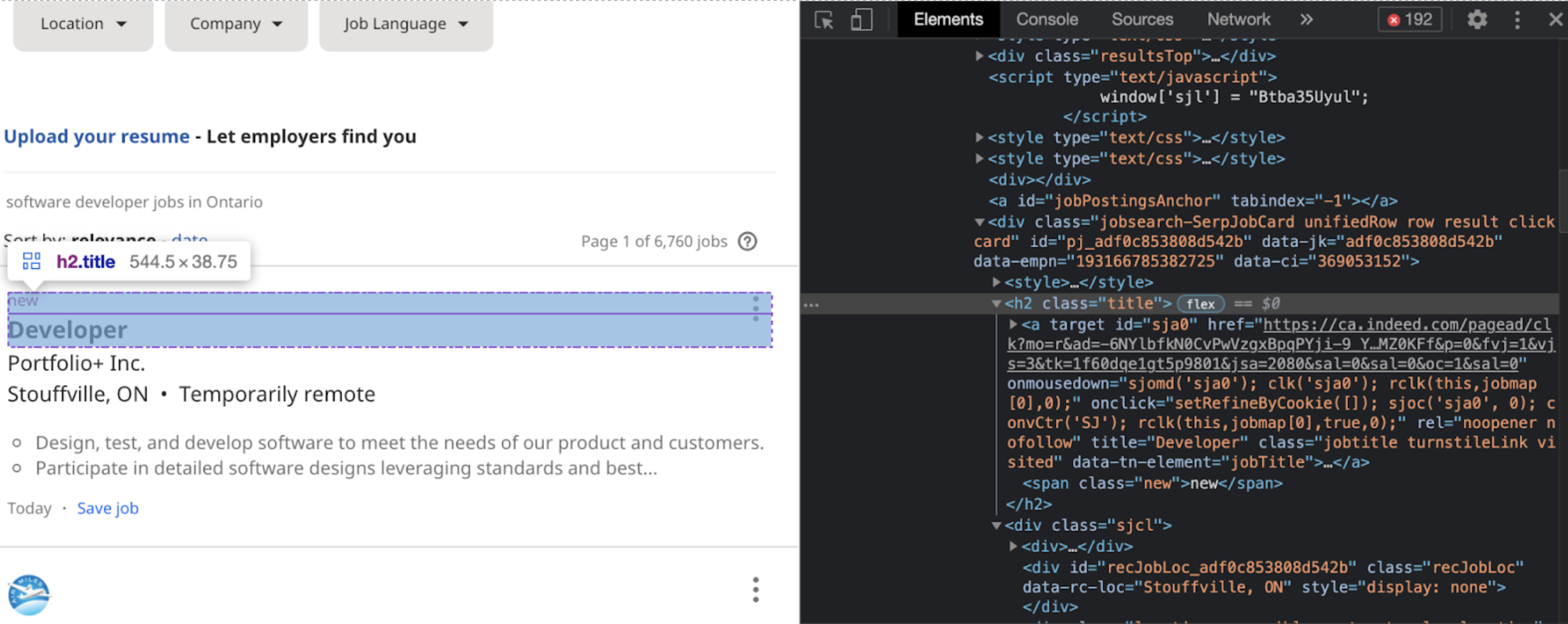
title_elem = job_elem.find('h2', class_ = 'title')
For company name, location, and remote option:

For company:

company_elem = job_elem.find('span', class_ = 'company')
For location:

location_elem = job_elem.find('div', class_ = 'location')
For remote:

remote_elem = job_elem.find('span', class_ = 'remote')
So final code for collecting the specific data we want we have:

Let’s check out what our output is. In order to do that we can pull out the text from each element using .text:
print(f'Job title: {title_elem.text}')
print(f'Company: {company_elem.text}')
print(f'Location: {location_elem.text} \n')
print(f'Job title: {title_elem.text.strip()}') print(f'Company: {company_elem.text.strip()}') print(f'Location: {location_elem.text.strip()} \n')
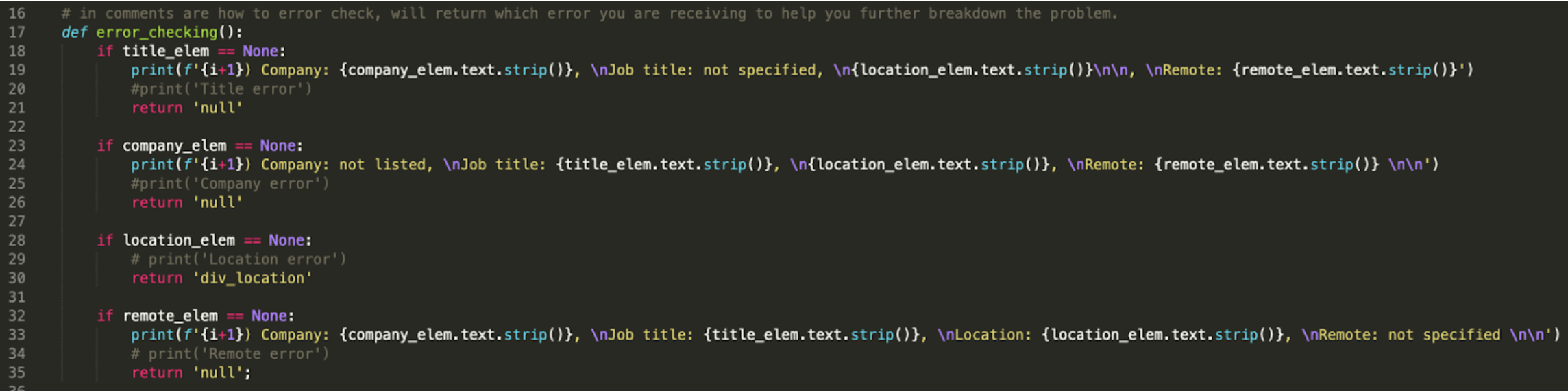
You do not need to define a function to error check, in fact I had initially done it all in the for-loop. But I wanted to practice making and applying functions. So first we need to define out function:
def error_checking():
Next, we want to look at our different cases:
if title_elem == None:print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: not specified, \n{location_elem.text.strip()}\n\n, \nRemote: {remote_elem.text.strip()}')
return 'null'
if company_elem == None:print(f'{i+1}) Company: not listed, \nJob title: {title_elem.text.strip()}, \n{location_elem.text.strip()}, \nRemote: {remote_elem.text.strip()} \n\n')
return 'null'
if location_elem == None:return 'div_location'
if remote_elem == None:print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: {title_elem.text.strip()}, \nLocation: {location_elem.text.strip()}, \nRemote: not specified \n\n')
return 'null';
Our final error checking function code is:
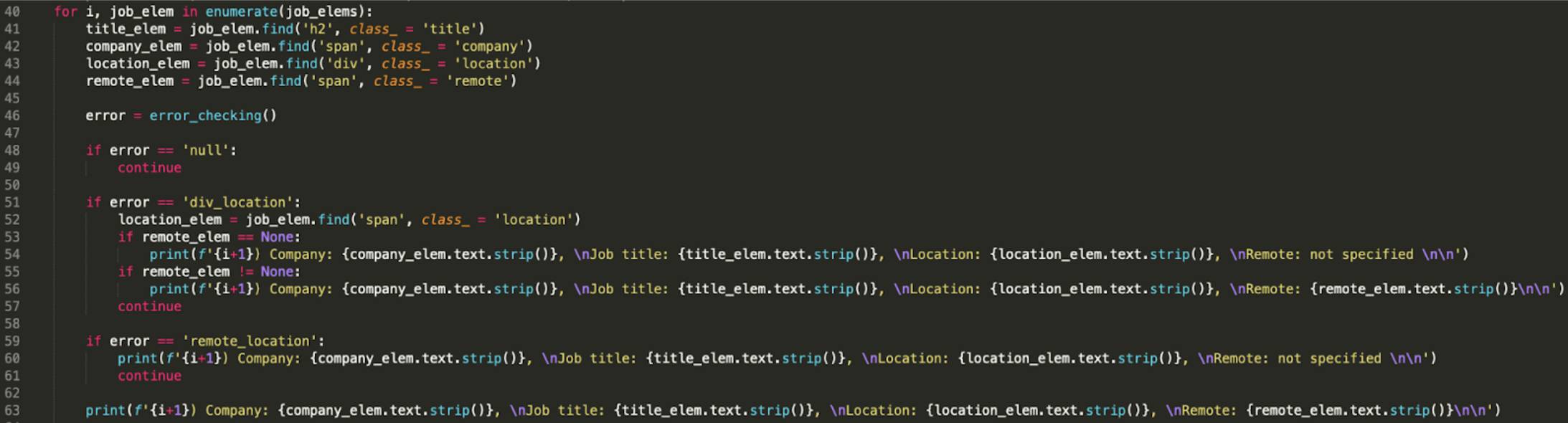
Within our for-loop we must now call the error function. Reminder, here is the for-loop code so far:
for i, job_elem in enumerate(job_elems):title_elem = job_elem.find('h2', class_ = 'title')
company_elem = job_elem.find('span', class_ = 'company')
location_elem = job_elem.find('div', class_ = 'location')
remote_elem = job_elem.find('span', class_ = 'remote')
We will call the error_checking() function
error = error_checking()
As you will have noticed, rather than just calling the function I decided to name a variable that calls the function. The reason for this is, if a variable is not used the error_checking() will be called more than once and can rewrite over the data giving different results depending on the order in which it is called. By putting the variable, you ensure that it is just called once and the result is store.
The first case that we will look at is if the error_checking() returned null, meaning that all that needs to happen is to skip this iteration of the for-loop and move to the next one (since we already have the information we want printed). We will get it to skip to the next iteration by writing continue.
if error == 'null':continue
The next case we have to look at is the location error. So we know if the error_checking() returns ‘div_location’, we have an issue with the scraping of the location information so we would like to write over the location_elem variable to contain the correct data:
if error == 'div_location':location_elem = job_elem.find('span', class_ = 'location')
The problem I ran into after doing this, is when both the location and the remote element are none we get no data returned. So in order to prevent that, we must check if remote_elem is none within the if statement of error == 'div_location':
if remote_elem == None:print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: {title_elem.text.strip()}, \nLocation: {location_elem.text.strip()}, \nRemote: not specified \n\n')if remote_elem != None:print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: {title_elem.text.strip()}, \nLocation: {location_elem.text.strip()}, \nRemote: {remote_elem.text.strip()}\n\n')
continue
Finally, if there are no exceptions (“errors”) we want to have all the information printed:
print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: {title_elem.text.strip()}, \nLocation: {location_elem.text.strip()}, \nRemote: {remote_elem.text.strip()}\n\n')
So altogether the final program will look like:
Along the way I had been given errors and I had a hard time figuring out where they came from, so I used “try”, “except” and “breakpoint()”. You can read more about them on the "fun things learnt" page.
So what I did was:
try:print(f'{i+1}) Company: {company_elem.text.strip()}, \nJob title: {title_elem.text.strip()}, \nLocation: {location_elem.text.strip()}, \nRemote: {remote_elem.text.strip()}\n\n')except:
breakpoint()